Browse Some of my Projects
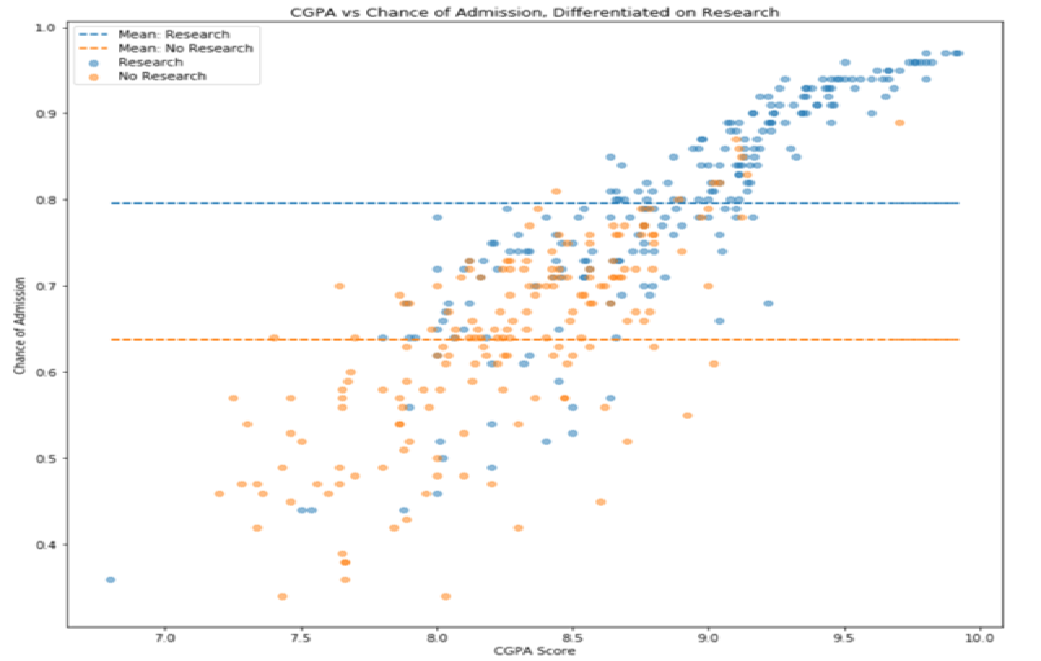
Graduate Level Admissions Analysis
Data Analysis & Visualization | Using python to perform basic statistics, data analysis, and visualizations of graduate school admissions data.
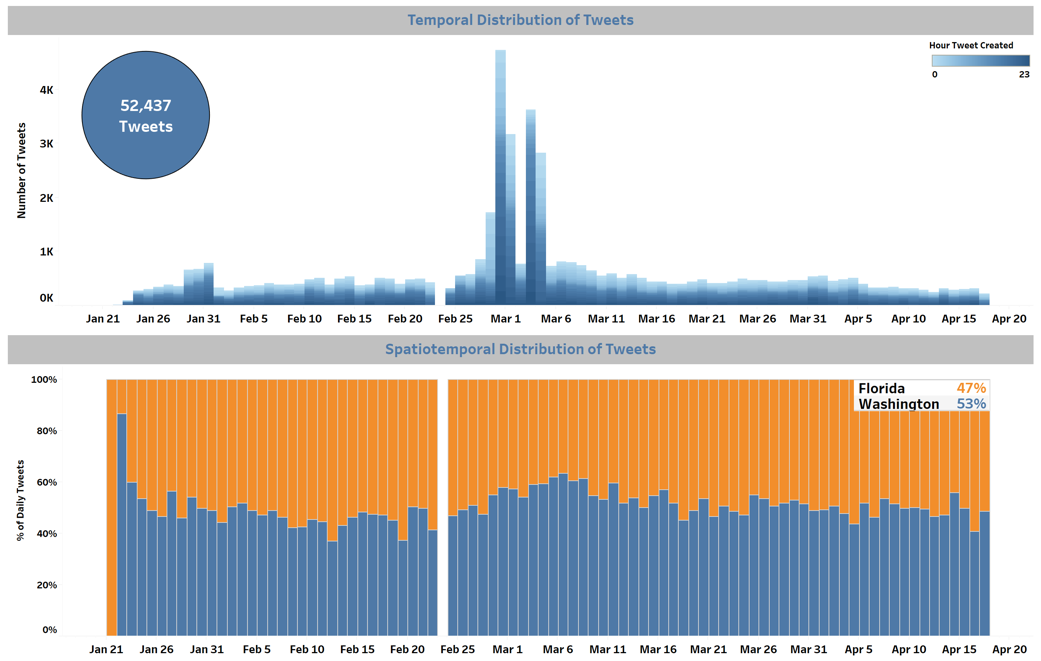
COVID-19 Policy Sentiment Analysis using Twitter
Natural Language Processing & Machine Learning | Using python and command line tools to scrape tweets on COVID-19, perform topic modeling using a latent dirichlet allocation model to understand what topics were being discussed, and performing sentiment analysis on those tweets in each topic.
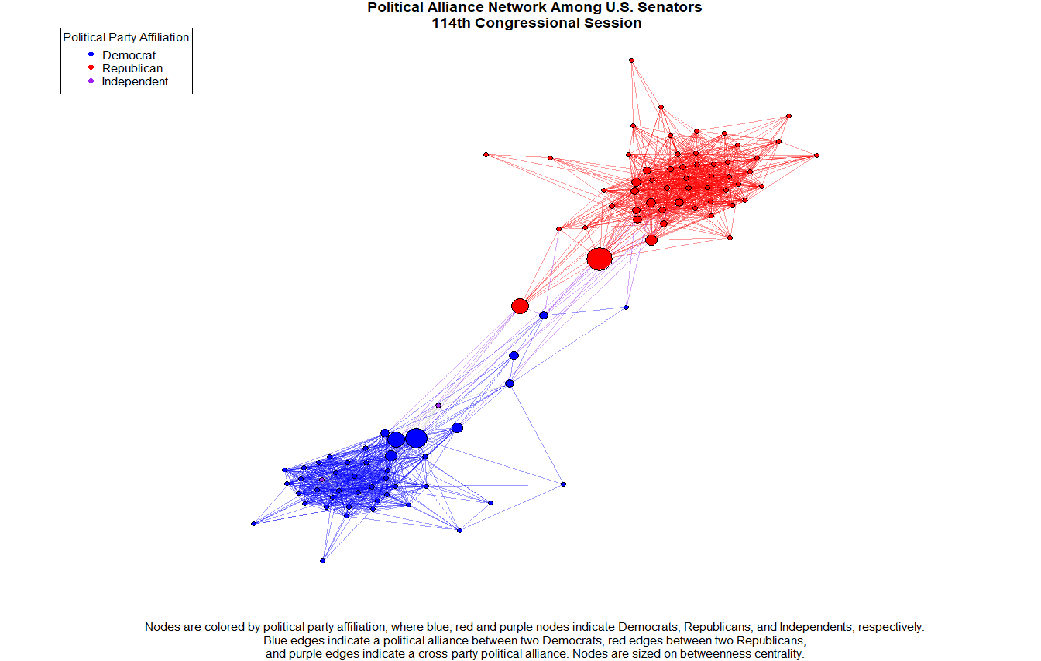
Statistical Network Analysis of Strong and Weak Polarization in the U.S. Senate
Statistics & Network Analysis | Using R to analyze networks of political alliances and discord among the U.S. Senate. Built Latent Position Cluster and Exponential Random Graph models on the output of a stochastic degree sequence model to measure partisan polarization.
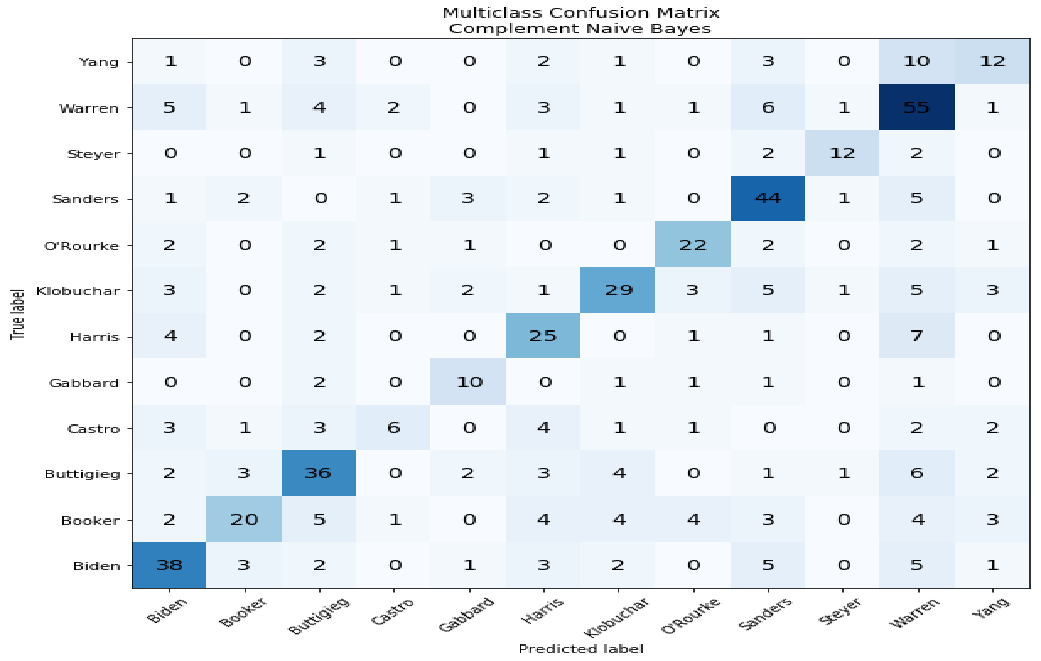
Supervised & Semi-supervised Text Classification
Natural Language Processing & Machine Learning | Using python to pre-process text, do some feature engineering, and build and evaluate supervised & semi-supervised text classification models to predict which U.S. Democratic Presidential Candidate said a certain quote.
Traffic Impacts of COVID-19
Statistics & Data Visualization | Using python and tableau to analyze and visualize Washington State Department of Transportation traffic data in Seattle to confirm the widely held belif that traffic volumes decreased after the onset of COVID-19.
Note: The Juptyer Notebook containing the statistical analysis and Tableau visualization is embedded on this page, right below the following image. Depending on how you are viewing this site, the formatting of the visualization may look poor, so I recommend going viewing it on the Tableau Public Website
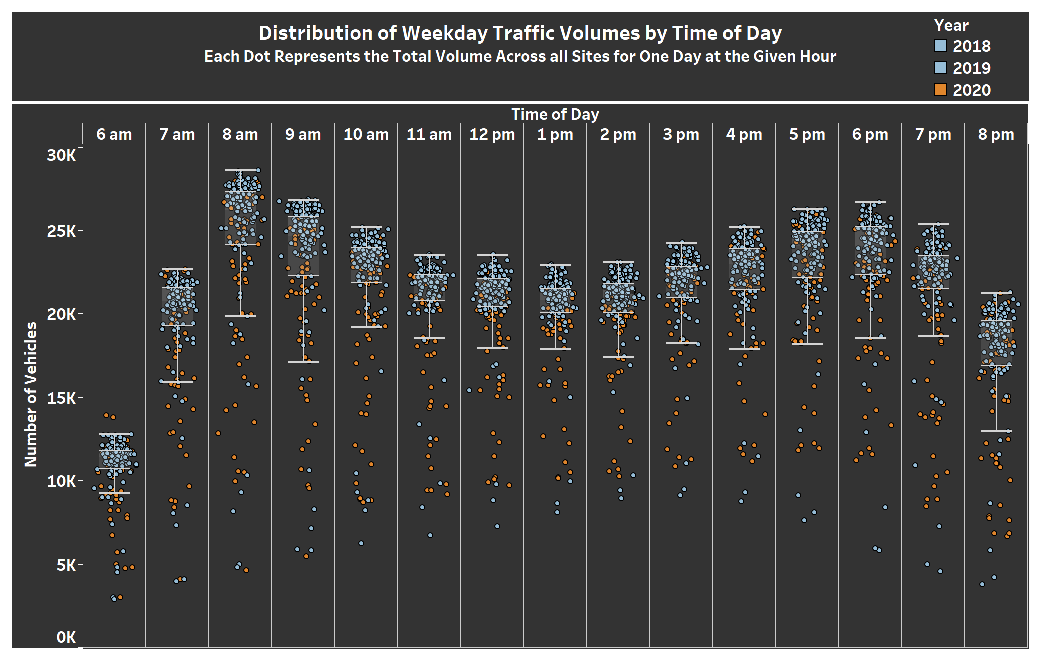
Hypothesis Testing | Decrease in Average Daily Traffic Volumes in Seattle, Washington during the Coronavirus Pandemic¶
The worksheet below examines statistical differences in traffic volumes in Seattle, in an attempt to quantify the reduction in traffic volumes at the onset of the Coronavirus Pandemic to 'normal' traffic volumes.¶
Data on traffic patterns in Seattle, Washington was collected from the Washington State Department of Transportation's (WSDOT) Traffic GeoPortal in June 2020. WSDOT uses permanent traffic recording devices to measure the number of vehicles per hour that pass by specific locations at every hour of each day. Data was gathered from seven sites in Seattle for the period ranging from January 1, 2018 through March 31, 2020 (the latest data available). After an initial exploration of the data, three sites were selected for further analysis due to significat data gaps in other sites. The three selected sites serve as a proxy for traffic volumes in Seattle due to their locations on major arterials that provide access to the city; the 520 bridge near its entrance to Interstate 5, Interstate 5 at NE 45th Street near the University of Washington, and Interstate 90 near Rainier Avenue. Each of these locations had several missing values, likely due to maintenance being performed on the devices, so a process of imputation was carried out in which missing values were replaced using mean substitution.¶
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------¶
Import Packages, Read in Data & Prepare it for Analysis¶
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------¶
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
from scipy.stats import t
from IPython.display import display, HTML
# Make the notebook's cells larger
display(HTML("<style>.container { width:70% !important; }</style>"))
traffic = pd.read_csv('CombinedTrafficData_Imputed_Values.csv')
traffic.head()
# Convert Date string into a Date Format
traffic['Date'] = pd.to_datetime(traffic['Date'])
# Select January, February, and March as our period of Observation
jfm_traffic = traffic[(pd.DatetimeIndex(traffic.Date).month < 4)]
# Add a separate column for Year, Month, and Day
jfm_traffic = jfm_traffic.assign(Year = pd.DatetimeIndex(jfm_traffic.Date).year,
Month = pd.DatetimeIndex(jfm_traffic.Date).month,
Day = pd.DatetimeIndex(jfm_traffic.Date).day)
# Group the data by date (Year, Month, Day) to collapse Travel Direction.
# Before grouping, there are two rows for each date, one for each direction of travel.
grouped_traffic = jfm_traffic.groupby(['Year','Month','Day'], as_index= False).sum()
# Add a new column that computes the total number of vehicles per day for each observation.
grouped_traffic['NumVehicles'] = grouped_traffic.iloc[:,3:27].sum(axis=1)
grouped_traffic.sample(5)
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------¶
Visualize the Distribution of Data - Bring in Tableau Visualization¶
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------¶
%%HTML
<div class='tableauPlaceholder' id='viz1596763938375' style='position: relative'><noscript><a href='#'><img alt=' ' src='https://public.tableau.com/static/images/5B/5BRFQMPTH/1_rss.png' style='border: none' /></a></noscript><object class='tableauViz' style='display:none;'><param name='host_url' value='https%3A%2F%2Fpublic.tableau.com%2F' /> <param name='embed_code_version' value='3' /> <param name='path' value='shared/5BRFQMPTH' /> <param name='toolbar' value='yes' /><param name='static_image' value='https://public.tableau.com/static/images/5B/5BRFQMPTH/1.png' /> <param name='animate_transition' value='yes' /><param name='display_static_image' value='yes' /><param name='display_spinner' value='yes' /><param name='display_overlay' value='yes' /><param name='display_count' value='yes' /><param name='language' value='en' /></object></div> <script type='text/javascript'> var divElement = document.getElementById('viz1596763938375'); var vizElement = divElement.getElementsByTagName('object')[0]; vizElement.style.width='100%';vizElement.style.height=(divElement.offsetWidth*0.75)+'px'; var scriptElement = document.createElement('script'); scriptElement.src = 'https://public.tableau.com/javascripts/api/viz_v1.js'; vizElement.parentNode.insertBefore(scriptElement, vizElement); </script>

In the visualization above, each dots represent the total traffic volumes for one day across the three sites for a given hour. Orange dots represent days that took place in 2020, and blue dots represent days in 2018 and 2019. It quickly becomes clear that many of the low traffic volumes occurred in 2020. However, several of the lowest volume days took place in February 2019, during Seattle's infamous Snowmaggedon: https://www.seattleweatherblog.com/snow/biggest-february-snowstorm-decades-blankets-seattle/¶
Hovering over the dots provides additional information, including the date, traffic volumes for each site, and direction of traffic.¶
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------¶
Is there a statistical difference in the difference in traffic volumes in 2020 compared with the 2018-2019 period?¶
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------¶
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------¶
Alpha Level = .01¶
Null Hypothesis: There has been no change in mean daily traffic volumes in Seattle, Washington during the coronavirus pandemic compared to the same period in prior years.¶
Alternative Hypothesis: There has been a decrease in mean daily traffic volumes in Seattle, Washington during the coronavirus pandemic compared to the same period in prior years.¶
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------¶
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------¶
Statistical Significance for Jan-Mar 2018 & 2019 vs 2020; All Days¶
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------¶
# Split traffic into 2018-2019 grouping and 2020 grouping
traffic_2020 = grouped_traffic.loc[grouped_traffic['Year'] == 2020]
traffic_2018_2019 = grouped_traffic.loc[grouped_traffic['Year'] != 2020]
# Distribution of Traffic Volumes across the two groups measured by standard deviation
np.std(traffic_2020['NumVehicles']), np.std(traffic_2018_2019['NumVehicles'])
# The standard deviations are not equal - should use Welch's 2 sample, one-sided t-test.
# Create a function that calculates a one-tailed Welch's test statistic
def tstat(group1, group2):
avg_g1 = np.mean(group1['NumVehicles'])
avg_g2 = np.mean(group2['NumVehicles'])
std_g1 = np.std(group1['NumVehicles'], ddof = 1)
std_g2 = np.std(group2['NumVehicles'], ddof = 1)
num_obs_g1 = len(group1['NumVehicles'])
num_obs_g2 = len(group2['NumVehicles'])
numerator = avg_g1 - avg_g2
denominator = np.sqrt( (std_g1**2/num_obs_g1) + (std_g2**2/num_obs_g2) )
degrees_freedom = ((std_g1**2/num_obs_g1) +
(std_g2**2/num_obs_g2))**2 / ((std_g1**4)/((num_obs_g1**2)*(num_obs_g1-1)) +
(std_g2**4)/((num_obs_g2**2)*(num_obs_g2-1)))
welchs_t_stat = numerator/denominator
return welchs_t_stat, degrees_freedom
print("T-Statistic:{}\nDegrees of Freedom: {}".format(tstat(traffic_2020, traffic_2018_2019)[0],
tstat(traffic_2020, traffic_2018_2019)[1]))
jfm_pval = stats.t.sf(np.abs(tstat(traffic_2020, traffic_2018_2019)[0]), tstat(traffic_2020, traffic_2018_2019)[1])
print("P Value: {}".format('%.10f' % jfm_pval))
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------¶
We Can Reject the Null Hypothesis¶
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------¶
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------¶
Statistical Significance for Jan-Mar 2018 & 2019 vs 2020; Weekdays Only¶
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------¶
# Create a copy of the dataframe
jfm_traffic_weekdays = jfm_traffic.copy()
# Remove Saturday and Sundays from the data
jfm_traffic_weekdays = jfm_traffic_weekdays.loc[(jfm_traffic_weekdays.DayOfWeek != 'Saturday') &
(jfm_traffic_weekdays.DayOfWeek != 'Sunday')]
# Group the data by date and add a column to calculate the total number of vehicles per day for each observation.
grouped_traffic_weekdays = jfm_traffic_weekdays.groupby(['Year','Month','Day'], as_index= False).sum()
grouped_traffic_weekdays['NumVehicles'] = grouped_traffic_weekdays.iloc[:,3:27].sum(axis=1)
grouped_traffic_weekdays.sample(5)
# Split traffic into 2018-2019 grouping and 2020 grouping
traffic_2020_weekdays = grouped_traffic_weekdays.loc[grouped_traffic_weekdays['Year'] == 2020]
traffic_2018_2019_weekdays = grouped_traffic_weekdays.loc[grouped_traffic_weekdays['Year'] != 2020]
print("T-Statistic:{}\nDegrees of Freedom: {}".format(tstat(traffic_2020, traffic_2018_2019_weekdays)[0],
tstat(traffic_2020, traffic_2018_2019_weekdays)[1]))
weekday_pval = stats.t.sf(np.abs(tstat(traffic_2020_weekdays, traffic_2018_2019_weekdays)[0]),
tstat(traffic_2020_weekdays, traffic_2018_2019_weekdays)[1])
print("P Value: {}".format('%.10f' % weekday_pval))
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------¶
We can Reject the Null Hypothesis¶
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------¶
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------¶
Statistical Significance for Mar 2018 & 2019 vs Mar 2020 Weekdays Only¶
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------¶
# Follow similar steps above, grouping by date and creating a column to calculate
# the total number of vehicles per day for each observation. Then exlude January and February.
mar_traffic_weekdays = jfm_traffic_weekdays.copy()
mar_traffic_weekdays = mar_traffic_weekdays[(pd.DatetimeIndex(mar_traffic_weekdays.Date).month == 3)]
mar_grouped_traffic_weekdays = mar_traffic_weekdays.groupby(['Year','Month','Day'], as_index= False).sum()
mar_grouped_traffic_weekdays['NumVehicles'] = mar_grouped_traffic_weekdays.iloc[:,3:27].sum(axis=1)
mar_grouped_traffic_weekdays.sample(5)
# Split traffic into 2018-2019 grouping and 2020 grouping
mar_traffic_2020_weekdays = mar_grouped_traffic_weekdays.loc[mar_grouped_traffic_weekdays['Year'] == 2020]
mar_traffic_2018_2019_weekdays = mar_grouped_traffic_weekdays.loc[mar_grouped_traffic_weekdays['Year'] != 2020]
print("T-Statistic:{}\nDegrees of Freedom: {}".format(tstat(mar_traffic_2020_weekdays, mar_traffic_2018_2019_weekdays)[0],
tstat(mar_traffic_2020_weekdays, mar_traffic_2018_2019_weekdays)[1]))
mar_weekday_pval = stats.t.sf(np.abs(tstat(mar_traffic_2020_weekdays, mar_traffic_2018_2019_weekdays)[0]),
tstat(mar_traffic_2020_weekdays, mar_traffic_2018_2019_weekdays)[1])
print("P Value: {}".format('%.10f' % mar_weekday_pval))
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------¶
We can Reject the Null Hypothesis¶
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------¶
print("P Value for All Days, January 1 - March 31: {}\nP Value for Weekdays Only, January 1 - March 31: {}\n"
"P Value for Weekdays Only, March 1 - March 31: {}".format('%.10f' % jfm_pval, '%.10f' % weekday_pval, '%.10f' % mar_weekday_pval))
All tests yielded statistically significant results at the .01 alpha levels, allowing us to reject the null hypothesis that there has been no change in mean daily traffic volumes in Seattle, Washington during the coronavirus pandemic compared to the same period in prior years. It can be difficult to compare p values when they are so small, so below we rescale them and plot them.¶
plt.figure(figsize=(8, 8))
plt.scatter(['All Months\nAll Days', 'All Months\nWeekdays', 'March\nWeekdays'],
[jfm_pval*10000000, weekday_pval*10000000, mar_weekday_pval*10000000])
plt.title('Rescaled P-Values')
plt.ylabel('P-Values multiplied by 10M')

The chart above shows rescaled p values so we can get a sense of the strongest test (lowest p value), which appear to be weekdays in March. This makes sense, as many companies started encouraging employees to work from home in March, and Governor Inslee's Stay Home Order was issued on March 23, 2020.¶
Notes¶
OVERVIEW, STEPS, AND PROCESS FOR NOT INCLUDING ALL SITES AND IMPUTING MISSING VALUES¶
ISSUES WITH SITES¶
- Site D10 did not have any data for February 2019
- Site R49R did not have any data for January 2020
- Site R017 did not have any data for westbound traffic in March 2018
- Site S202 did not have any data for northbound traffic in 2018 or southbound traffic in 2019
All of these sites are excluded from the analysis
IMPUTING MISSING VALUES FOR REMAINING SITES¶
The remaining sites (R046, R117, and S502) all had missing data values for certain days or direction (north/south, east/west) on a certain day. These missing values were imputed by calculating the mean traffic volumes for that day of the week on the year/month combination. For example, if there was no data for Sunday March 11, 2018, the mean traffic volume for Sundays in March of 2018 was calculated and assumed to be the traffic volume for that day. The time of day was ignored, and each hour was given the same traffic volume such that each hour summed together for Sunday March 11, 2018 would equal the average traffic volume for Sundays in March 2018. To ensure that values were whole numbers and estimates were conservate, the FLOOR function was used" FLOOR((Avg Num Vehicles/24),1)
For the sites that were included in the analysis, the following days and directions had missing values:¶
- Site R046:
- March 11, 2018
- March 25, 2018 (southbound only)
- February 23, 2019 (northbound only)
- March 10, 2019
- January 17, 2020 (southbound only
- March 8, 2020
- Site R117:
- February 18, 2018 (westbound only)
- March 11, 2018
- March 10, 2019
- February 4, 2020 (westbound only)
- February 5, 2020 (westbound only)
- February 11, 2020
- February 12, 2020
- March 8, 2020
- Site S502:
- March 11, 2018
- March 10, 2019
- January 28, 2020 (eastbound only)
- March 8, 2020